-
论文名称:Cooperative Holistic Scene Understanding: Unifying 3D Object, Layout, and Camera Pose Estimation
-
论文作者:Siyuan Huang, Siyuan Qi, Yinxue Xiao, Yixin Zhu, Ying Nian Wu, Song-Chun Zhu(来自UCLA)
-
收录情况:NeurIPS 2018
简介
虽然人类能比较容易的感知一个3D场景(200ms内完成;Potter, 1975, 1976, Schyns and Oliva, 1994, Thorpe et al., 1996),但是3D场景的整体理解在计算机视觉研究中是个基础又有挑战性的问题,主要的困难是:单张RGB图片包含大量带有歧义的3D信息。3D场景整体理解包含几项任务:
- 相机3D姿态估计。RGB图片来自相机,搞清楚相机在哪个位置,从哪个角度拍摄了照片,有助于提升2D图片和3D场景的一致性 $consistency$。
- 场景3D布局估计。通常指室内场景,相机3D姿态与场景3D布局组合起来,能反映场景的全局几何性质 $global ~geometry$。
- 场景中物体3D检测。反映的是局部信息 $local~ details$
本文要解决的问题:
- 2D-3D consistency. 2D像平面和3D世界的一致性
- Cooperation. 人类感知系统非常擅长融合不同视觉信息,设计算法时应当遵循这样的原则,让不同模块协同工作
- Physically Plausible. 建模出来的3D场景,应该能用物理世界解释
一些已知的方法或者不够高效,或者解决了部分问题
相关工作
- Traditional Methods
- Abhinav Gupta, Martial Hebert, Takeo Kanade, and David M Blei. Estimating spatial layout of rooms using volumetric reasoning about objects and surfaces. In Conference on Neural Information Processing Systems (NIPS), 2010
- Yibiao Zhao and Song-Chun Zhu. Image parsing with stochastic scene grammar. In Conference on Neural Information Processing Systems (NIPS), 2011
- Wongun Choi, Yu-Wei Chao, Caroline Pantofaru, and Silvio Savarese. Understanding indoor scenes using 3d geometric phrases. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2013
- Yinda Zhang, Shuran Song, Ping Tan, and Jianxiong Xiao. Panocontext: A whole-room 3d context model for panoramic scene understanding. In European Conference on Computer Vision (ECCV), 2014
- Hamid Izadinia, Qi Shan, and Steven M Seitz. Im2cad. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
- Siyuan Huang, Siyuan Qi, Yixin Zhu, Yinxue Xiao, Yuanlu Xu, and Song-Chun Zhu. Holistic 3d scene parsing and reconstruction from a single rgb image. In European Conference on Computer Vision (ECCV), 2018
- Alexander G Schwing, Sanja Fidler, Marc Pollefeys, and Raquel Urtasun. Box in the box: Joint 3d layout and object reasoning from single images. In IEEE International Conference on Computer Vision (ICCV), 2013
- Deep Learning, training individual modules separately
- Arsalan Mousavian, Dragomir Anguelov, John Flynn, and Jana Košecká. 3d bounding box estimation using deep learning and geometry. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
- Chen-Yu Lee, Vijay Badrinarayanan, Tomasz Malisiewicz, and Andrew Rabinovich. Roomnet: End-to-end room layout estimation. In IEEE International Conference on Computer Vision (ICCV), 2017
- Wadim Kehl, Fabian Manhardt, Federico Tombari, Slobodan Ilic, and Nassir Navab. Ssd-6d: Making rgb-based 3d detection and 6d pose estimation great again. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
- Abhijit Kundu, Yin Li, and James M Rehg. 3d-rcnn: Instance-level 3d object reconstruction via render-and-compare. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018
- Chuhang Zou, Alex Colburn, Qi Shan, and Derek Hoiem. Layoutnet: Reconstructing the 3d room layout from a single rgb image. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018
- Chen Liu, Jimei Yang, Duygu Ceylan, Ersin Yumer, and Yasutaka Furukawa. Planenet: Piece-wise planar reconstruction from a single rgb image. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018
- Shubham Tulsiani, Saurabh Gupta, David Fouhey, Alexei A Efros, and Jitendra Malik. Factoring shape, pose, and layout from the 2d image of a 3d scene. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018 —— without modeling relations explicitly
- Another Stream of Approaches, taking RGB-D image and camera pose as input
- Dahua Lin, Sanja Fidler, and Raquel Urtasun. Holistic scene understanding for 3d object detection with rgbd cameras. In IEEE International Conference on Computer Vision (ICCV), 2013
- Shuran Song and Jianxiong Xiao. Sliding shapes for 3d object detection in depth images. In European Conference on Computer Vision (ECCV), 2014
- Shuran Song, Fisher Yu, Andy Zeng, Angel X Chang, Manolis Savva, and Thomas Funkhouser. Semantic scene completion from a single depth image. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
- Zhuo Deng and Longin Jan Latecki. Amodal detection of 3d objects: Inferring 3d bounding boxes from 2d ones in rgb-depth images. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
- Chuhang Zou, Zhizhong Li, and Derek Hoiem. Complete 3d scene parsing from single rgbd image. arXiv preprint arXiv:1710.09490, 2017
- Charles R Qi, Wei Liu, Chenxia Wu, Hao Su, and Leonidas J Guibas. Frustum pointnets for 3d object detection from rgb-d data. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018
- Jean Lahoud and Bernard Ghanem. 2d-driven 3d object detection in rgb-d images. In IEEE International Conference on Computer Vision (ICCV), 2017
- Yinda Zhang, Mingru Bai, Pushmeet Kohli, Shahram Izadi, and Jianxiong Xiao. Deepcontext: Context-encoding neural pathways for 3d holistic scene understanding. In IEEE International Conference on Computer Vision (ICCV), 2017a
主要方法
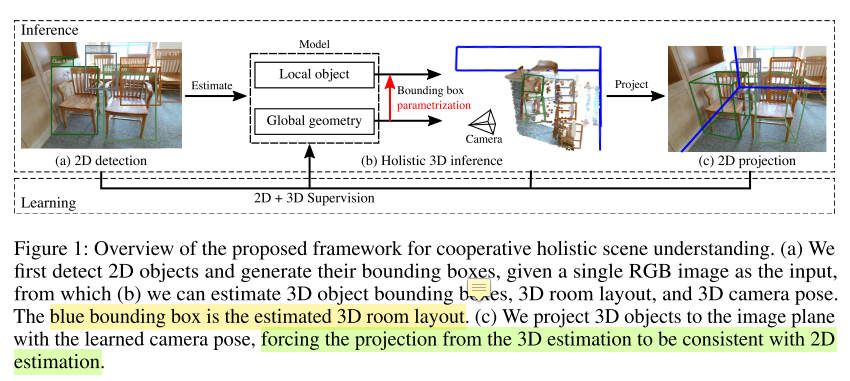
- 这部分主要描述 3D bbox 的参数化表示 $parametrization$(其实很简单)和用于3D scene understanding 的神经网络
- $global~ geometric~ network$: 3D room layout、camera pose
- $local~ object~ network$: 3d object
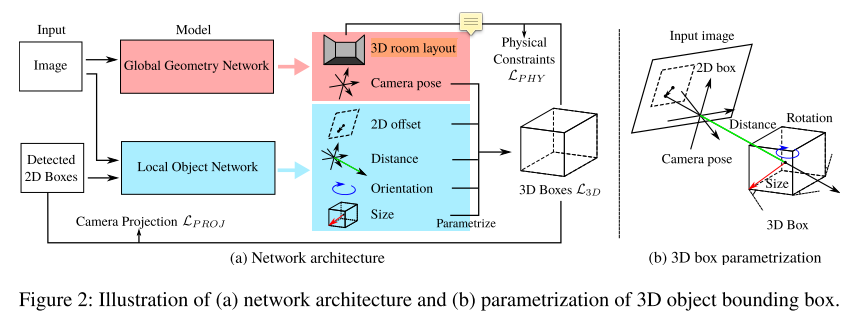
- Parametrization
- 3D objects
- $X^W \in \mathbb{R}^{3 \times 8}$ 表示世界坐标系中的3D物体,维度解释:立方体有8个顶点,每个顶点是3维向量
- 中心点 $C^W \in \mathbb{R}^{3}$不好求(RGB图片没有深度信息),分解为
- 物体在像平面2D bbox 中心 $C^{I} \in \mathbb{R}^{2}$
- 相机中心到3D物体的中心距离 $D$
- 相机内参 $K \in \mathbb{R}^{3 \times 3}$
- 相机外参 $R(\phi, \psi) \in \mathbb{R}^{3 \times 3}$,$T \in \mathbb{R}^{3}$,$\phi$和$\psi$是相机旋转角(理解为$roll$和$pitch$)
-
如上图所示,3D 物体中心投影到像平面,不一定与2D bbox重合,记这个偏移量为 $\delta^I \in \mathbb{R}^{2}$
- 综上,$C^W$ 可用下面公式计算(看起来很复杂,其实是相机投影模型的基本用法)
- \[C^W = T + DR(\phi, \psi)^{-1} \frac{K^{-1}[C^I + \delta^I, 1]^{T}}{\parallel K^{-1}[C^I + \delta^I, 1]^{T} \parallel_{2}}\]
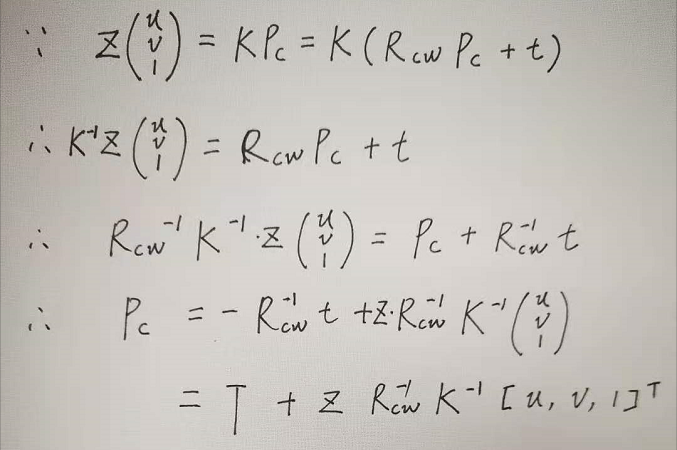
- 当相机坐标系原点与世界坐标系重合时,$T$ 变成 $\overrightarrow{0}$(是我的理解,原文是这么说的:从第一人称视角得到数据时,$T$ 变成 $\overrightarrow{0}$)
- 因此,可以记 $C^W = p(C^I, \delta^{I}, D, \phi, \psi, K)$,其中 $p$ 是可导的 $projection ~ function$
- 从3D box中心点 $C^W$ 的计算方式看,考虑了2D object center $C^I$,有助于维护2D-3D的一致性,减少3D bbox估计的方差(作者的观点,其实未必)。同时,里面集成了camera pose,体现了各个组件 $cooperative ~promoting$。
- 尺寸 $S^W \in \mathbb{R}^{3}$
- 方向 $R(\theta^{W}) \in \mathbb{R}^{3 \times 3}$,$\theta^{W}$ 是沿$z$轴线的方位角
- 组合起来,$X^W = h(C^W, R(\theta^{W}), S)$,$h(\cdot)$是边界框函数
- 3D Room Layout
- 与3D objects类似,$X^L \in \mathbb{R}^{3 \times 8}$
- 中心点 $C^L \in \mathbb{R}^{3}$
- 尺寸 $S^L \in \mathbb{R}^{3}$
- 方向 $R(\theta^{L}) \in \mathbb{R}^{3 \times 3}$,$\theta^{L}$ 是旋转角
- 3D objects
- Direct Estimations
- $global~geometry~network$(GGN)
- 输入:RGB图片
- 输出:3D room layout + 3D camera pose
- 3D room layout、3D camera pose的预测依赖于 global geometry features
- 损失函数:\(\mathcal{L}_{GGN} = \mathcal{L}_{\phi} + \mathcal{L}_{\psi} + \mathcal{L}_{C^L} + \mathcal{L}_{S^L} + \mathcal{L}_{\theta^L}\)
- $local~object~network$(LON)
- 输入:2D image patches(理解为图片的2D bbox)
- 输出:distance $d$ + size $S^W$ + heading angle $\theta^{W}$ + 2D offsets $\delta^{I}$
- 损失函数:\(\mathcal{L}_{LON} = \frac{1}{N} \sum_{j=1}^{N} (\mathcal{L}_{D_j} + \mathcal{L}_{\delta^{I}_j} + \mathcal{L}_{S^W_j} + \mathcal{L}_{\theta^W_j})\)
- $N$ 是场景中的物体数
- 直接拟合物体属性(e.g. 方位角)不是一个好的方法,可能导致大的误差,所以采用了另外一种方法:
- 预定义几个 size templates
- 首先把物体对应的属性(e.g. 方位角) 分类到一个template,然后在template内部预测属性误差
- 拿方位角举例,\(\mathcal{L}_{\phi} = \mathcal{L}_{\phi - cls} + \mathcal{L}_{\phi -reg}\)
- $global~geometry~network$(GGN)
- Cooperative Estimations
- 心理学实验表明:
- 人们对场景的感知依赖的是全局信息而不是局部细节(Oliva, 2005; Oliva and Torralba, 2006)—— gist of scene
- 人们对特定任务的理解,往往涉及多条视觉线索的合作(Landy et al., 1995; Jacobs, 2002)—— depth perception
- 本文Cooperative Estimations遵循同样的原则,让各模块相互配合,促进整个任务(其实就是把不同模块的损失函数加权求和——常见的用法,这篇文章特意强调)
- 3D Bounding Box Loss
- \[\mathcal{L}_{3D} = \frac{1}{N} \sum_{j=1}^{N} \parallel h(C^W_j,R(\theta_j),S_j) - X^{W*}_j \parallel_2^2\]
- $X^{W*}$ 是世界坐标系下的ground truth 3D bbox
- 2D Projection Loss
- \[\mathcal{L}_{PROJ} = \frac{1}{N} \sum_{j=1}^{N} \parallel f(X^W_j,R,K) - X^{I*}_j \parallel_2^2\]
- $f(\cdot)$ 是可导的投影函数,把3D bbox投影成2D bbox
- $X^{I*}_j \in \mathbb{R}^{2 \times 4}$ 是2D bbox ground truth(把检测到的当做2D bbox ground truth)
- Physical Loss
- \[\mathcal{L}_{PHY} = \frac{1}{N} \sum_{j=1}^{N} (ReLU(Max(X_j^W) - Max(X^L)) + ReLU(Min(X^L) - Min(X^W_j)))\]
- $ReLU$ 是激活函数,$Max(\cdot) / Min(\cdot)$的输入是$X^W, X^L$,输出沿 $x,y,z$ 三个轴的 max/min value,作者认为这样就把3D layout和3D object联系起来
- Total Loss
- \[\mathcal{L}_{Total} = \mathcal{L}_{GGN} + \mathcal{L}_{LON} + \lambda_{COOP}(\mathcal{L}_{3D} + \mathcal{L}_{PROJ} + \mathcal{L}_{PHY})\]
- 心理学实验表明:
实现
- GGN、LON的骨干网络采用ResNet-34,把 256x256 的图片编码成2048维向量(编码器)
- 预测时,在编码器上增加两个全连接层,最后输出 L 维的预测向量
- 2048 $\times$ 1024
- 1024 $\times$ L
- 预测时,在编码器上增加两个全连接层,最后输出 L 维的预测向量
- 训练过程分为2步
-
用30个common object categories调优2D detector([Dai et al., 2017; Bodla et al., 2017),然后生成 2D bbox,作为3D bbox投影的监督信息
-
训练2个3D estimation networks —— GGN和LON。先分别在synthetic dataset(Song et al., 2017; s Zhang et al. 2017b)上训练,获得初始化权重,再放到SUN RGBD数据集一起训练。
-
- 数据增强方法
- 随机翻转图片
- randomly shift 2D bboxes with corresponding labels during cooperative training(???第一次见这种操作)
实验评估
- Qualitative Results

- Quantitative Results
- 3D layout estimation
- IoU threshold 15%
- $P_g$:geometric precision
- $P_g$:geometric recall
- $R_r$:semantic recall
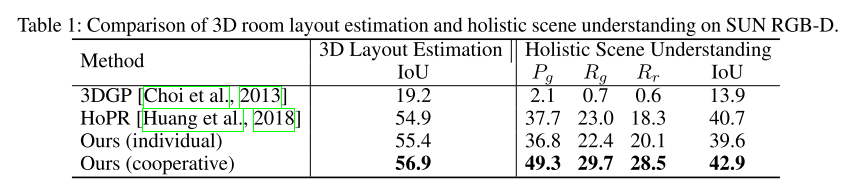
- IoU threshold 15%
-
3D object detection

-
3D box estimation

-
camera pose estimation
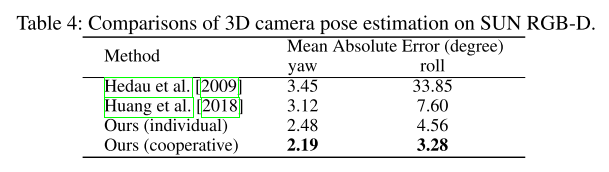
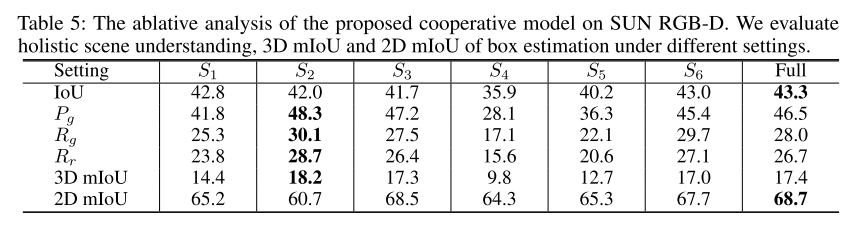
- Holistic Scene Understanding & Ablation Analysis
- The model trained without the supervision on 3D object bounding box corners (w/o L3D, S1).
- The model trained without the 2D supervision (w/o LPROJ, S2).
- The model trained without the penalty of physical constraint (w/o LPHY, S3).
- The model trained in an unsupervised fashion where we only use 2D supervision to estimate the 3D bounding boxes (w/o L3D + LGGN + LLON, S4).
- the model trained directly on SUN RGB-D without pre-train (S5)
- the model trained with 2D bounding boxes projected from ground truth 3D bounding boxes (S6)

- 3D layout estimation